

 Now days, the NoSql databases have become more prominent. I see people around me wondering how to design these non-relational databases. The Wikipedia describes NoSQL properties like “They do not completely guarantee atomicity, consistency, and durability, and usually scale horizontally well”. So, the schema are fully dynamic (you could add in runtime entities and fields). Although, thinking just in how the data is stored and how are distributed over the partitions is just one side of the coin, the Infrastructure side. Just because the data are not physically and strongly cohesive, it does not imply that the data schema lacks structure in the other domains.
Now days, the NoSql databases have become more prominent. I see people around me wondering how to design these non-relational databases. The Wikipedia describes NoSQL properties like “They do not completely guarantee atomicity, consistency, and durability, and usually scale horizontally well”. So, the schema are fully dynamic (you could add in runtime entities and fields). Although, thinking just in how the data is stored and how are distributed over the partitions is just one side of the coin, the Infrastructure side. Just because the data are not physically and strongly cohesive, it does not imply that the data schema lacks structure in the other domains.
In this context, if we analyse the concepts in the business domain, we observe that the concepts are related each other in a directly of indirectly manner. To illustrate this topic better, let’s think about a functionality, for example a selling “books functionality”. Concepts such as: customer, inventory, sale, etc. They make sense within the functionality directly: if the customer concept does not exist, the concept of sale does not exist, the same thing happens if the inventory concept does not exist. In the other hand, some abstract nature concepts such as: writers reputation or illiteracy index, etc. They affect functionality because they have an indirect effect on the sales concept. In the first case, if the writers reputation increases then the sales have a high probability of rising, the same effect happens in the opposite direction. In the second example, if the illiteracy rate rises, the sales probability goes down, and the same thing happens in the opposite direction. This causality between concepts is what defines the inherent relationship that exists between them (This topic will be part of another entry about linked-data 🙂 ).
But then, how important is this causality in NoSQL databases?. It implies that when modifying / adding / removing fields or concepts dynamically, these causal relationships between concepts must be taken into account. (Note that there is no talk about an entity-relationship model at any time).
Before start: A meta-model is a model of a model, and meta-modelling is the process of generating those meta-models. Thus, the meta-modelling is the analysis, construction and development of the frameworks, rules, restrictions, models and theories applicable and useful for modelling a predefined class of problems. As the name implies, this concept applies the notions of goal and modelling in software engineering and systems engineering
Proposal
To illustrate this let’s break down a simple concept of “Person” for the two kind of NoSQL data bases: the documental databases and graph databases. The models we are using to describe the NoSQL databases are:
- Conceptual Model and Meta-model: It will allow to understand the relationship and the organization of possible high-level concepts describing them in more than one domain. Therefore, we will use the Information Archimate Viewpoint.
- Logical meta-model: Allows to visualize all the fields susceptible to be used in the concepts. For this, we are going to use a UML class diagram. There is a correspondence between class and concept.
- Physical model and meta-model: This model extends the logical meta-model and describes the different ways in which a concept or scheme can be physically stored. This visualization allows to verify the conceptual and logical models/meta-models. Later, it could be useful to visualize the databases status in a certain moment of time. For this we are going to use a UML class diagram (it can also be a diagram of UML objects diagram).
Conceptual Model and Meta-model
Behind a two dimensions model is described. In the business dimension, the concept Person is described. In the application dimension, the Person concept is broken down into three entities: Person is composed with Identification, and Person aggregates Address. Then, a person must have at least one identification concept and might have one or more Address concepts.
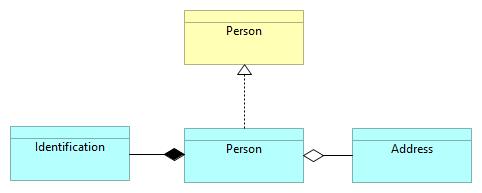
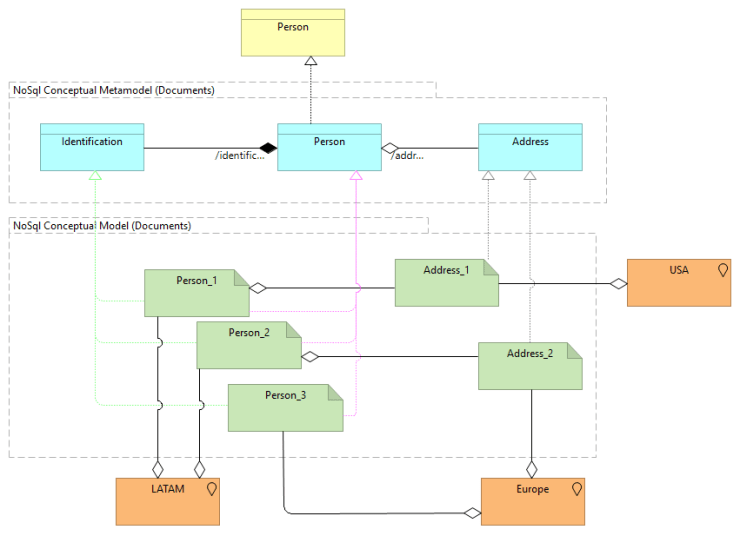
Next, a documental database example is described. Then, an infrastructure domain appears, it describes the type o documents allowed to be created in the NoSQL database. Each concept will be stored in a document, and a document could store more than one nested concept. For example, Identification an Person are saved in the same artifact (ArchiMate artifact) called Person. Finally, the Address artifact store just the Address concept.

The JSON description of Person will be similar to this:
{ "Nombre": "String", "FechaNacimiento": "Number", "Genero": "String", "address_id": "ref (Address)", "identification": ["identification_1", "identification_2"] }
The model above does NOT involve a database with just two documents. It is just a representation of the document TYPES involved that could be stored in the NoSQL database. If you want to be more explicit with the design, you can add more artifacts in the infrastructure domain, which can be used to describe how to scale the databases horizontally, or by just as an example.
Next, we see the complete design. It has two parts:
- The domain of application is conceived as the conceptual meta-model of a documental database.
- And the infrastructure domain is conceived as the conceptual model
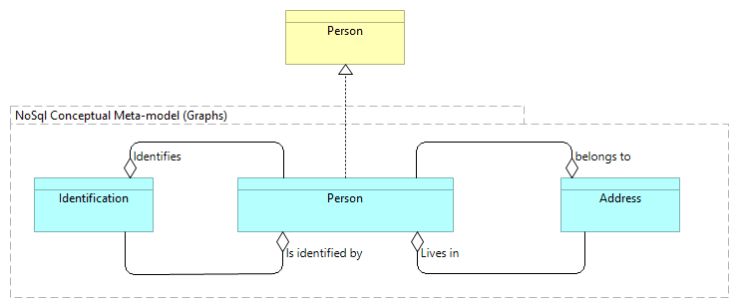
The meta-conceptual model has the appearance as seen below for the graph databases. In the meta-model, the same three entities described above are also described, but in this case, the relationships are back and forth between entities. As a result, Person is identified by an Identification, Identification identifies a Person, Person lives in an Address and an Address belongs to one or several Person. This model is the basis for later building the graphs.
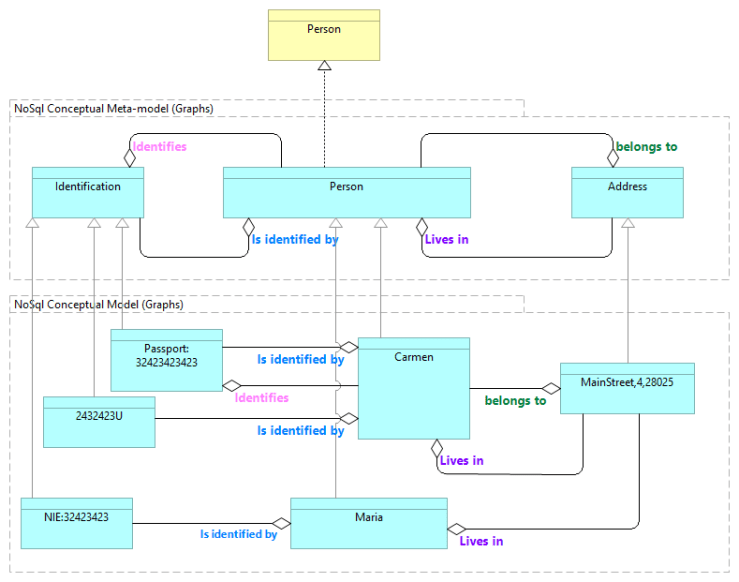
In this way, the meta-model describes the rules of the relationships which the final graph is later physically constructed. Next, we add a Graph Model example, it allows us to validate the meta-model. The model concepts inherit the meta-model concepts to test if the final graph model will fit our relationship needs.
Logical meta-model
Now, the logical meta-model will be described. The documental database is the first to be described, each class corresponds to a concept identified in the conceptual meta-model. We add the properties to each concept. The property must describe a name and type (strings, numbers, etc.), and also the cardinality between classes. The relationships between concepts are the ones described within a NoSQL document.
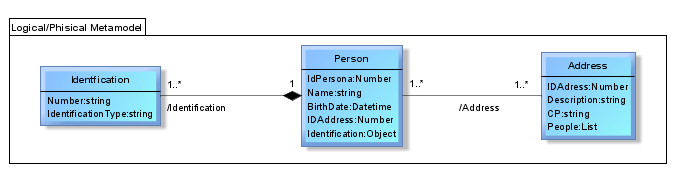
If it is a graph database desing, we also describe all the possible properties and types. But when we describe the relationship we have to describe the back and forth relationships as we do in the conceptual meta-model.
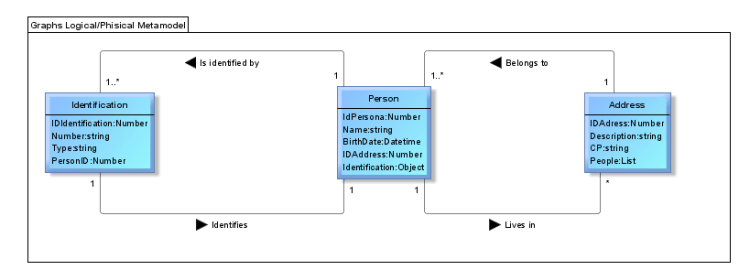
A meta-logical model is defined and not as a logical model. Then, instead of describing a future logical model, a pattern of how a NoSQL database should grow and evolve is described. In this context, it is usefull as a guide to know how to relate new concepts, or add correctly a property to the appropriate concept, besides, have a reference of the type it should have. In conclusion, it helps us to measure the impact when the scheme has to evolve.
Physical model and meta-model
The physical meta-model can become similar or the same as the logical meta-model. If the fields notation and data types correspond physically with a specific database engine it will be called physical meta-model. The purpose of the physical meta-model is the same as that of the logical meta-model: “describe a pattern of how the database should grow”. Use a single meta-logical / physical meta-model or separate them into two different meta-models, will depend on the visualization needs. In this example both meta-models are the same.
The physical model, on the other hand will inherit the concepts defined in the meta-model for both NoSQL databases: the documental database and the graph database. This model can help verify the physical meta-logical model and provide data validation rules.
For the documental model, the classes that represent the physical documents. The nested concepts could be shown with nested classes. The fields can vary between class and class, but they always must fit with the physical meta-model. An example rule to validate: for each Identification, it must have at least one property describing the Number even if IdentificationType could not be determined.
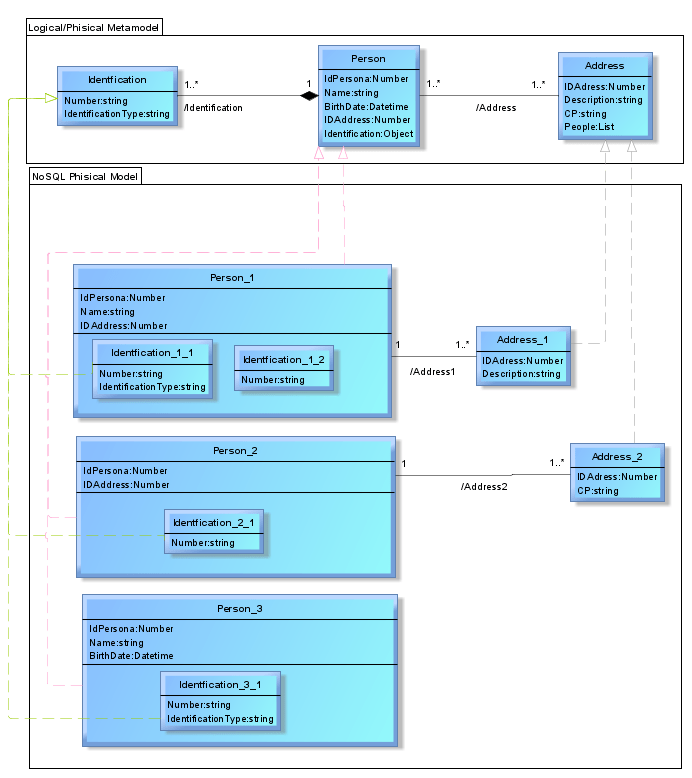
In the case of the graph model, each class represents a node of the graph and each node will inherit a concept of the physical meta-model and must respect its relationships. The properties of the node class could contain one ore more of the defined ones in the physical meta-model. The following model describes what was described, the graph example is produced by the meta-model. If an UML object diagram is used, the objects in the diagram are instances of the physical meta-model classes.
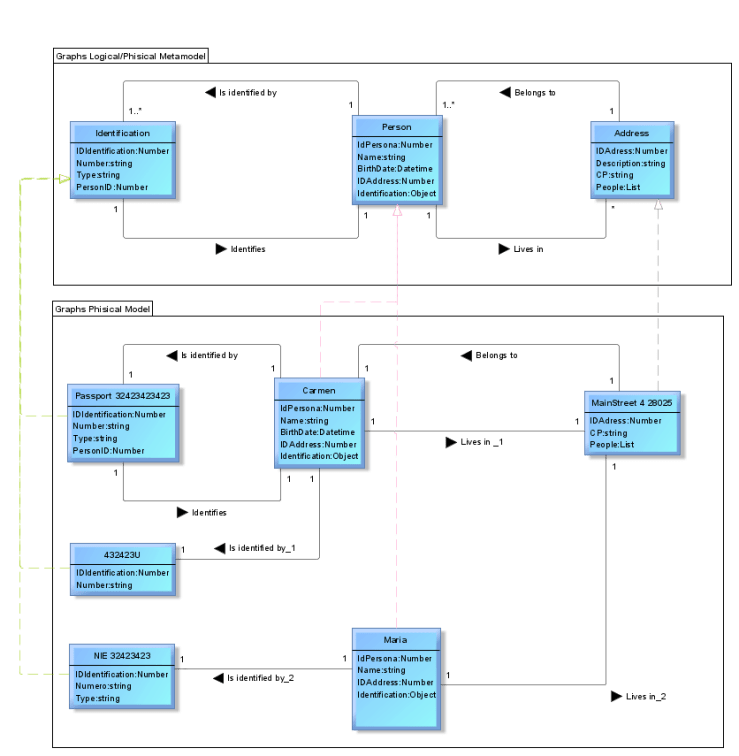
Conclusions
The current technology, gives us a great versatility in the way the data is stored, searched, and structured to be more efficient. The main idea is to show a broader vision that goes beyond the implementation of schemas in data engines. In this post we have been able to observe how the concepts are related between the different domains. This vision can be useful if you are a large company and you have large volumes of data to govern, or if you are a small startup that is looking for patterns between concepts and then apply AI, to name some examples.
Finally, As a final reflection, it is necessary to keep in mind that each of the concepts stored in any relational / non-relational database engine is more than a record or a file. The concepts surond us and are alive even for those who lack knowledge of software and computer engineering.
References
https://en.wikipedia.org/wiki/Metamodeling
https://modeling-languages.com/discovery-and-visualization-of-nosql-database-schemas/
http://www.dataversity.net/data-modeling-nosql-mongodb/
https://neo4j.com/developer/guide-data-modeling/
https://docs.mongodb.com/manual/core/data-modeling-introduction/

Thanks your reference 🙂
LikeLike